

Привіт! Напевно, ви, як і я, щодня стикаєтеся з новинами про штучний інтелект та його неймовірні можливості. Особливо популярні зараз ШІ-помічники — розумні чат-боти, які, здається, ось-ось почнуть розуміти нас з півслова та виконувати будь-які завдання. Але ми з вами на фриланс-платформі, тому будемо говорити про створення ШІ-помічників.
Написати цю статтю я вирішив після того, як поспілкувався з кількома замовниками і зрозумів, що в їхньому уявленні створення такого помічника — це як налаштувати просту програму. Тому я вирішив написати статтю, яка допоможе вам зрозуміти етапи створення такого помічника.
Для початку я хотів би представитися. Мене звати Андрій. Якщо ви подивитеся моє портфоліо, то помітите, що основна спеціалізація — це SEO. Так, це правда. Але з появою ШІ я досить серйозно захопився цією технологією і зараз можу сказати, що розбираюся в цьому не гірше, ніж у SEO. Загалом, я по-справжньому захоплений ШІ-моделями та повсюдно їх використовую. Зараз я розробляю два проєкти з використанням ШІ: перший – освітній, а другий – для спрощення SEO-завдань. Крім того, я зробив кілька проєктів для клієнтів. Важливо додати, що зазвичай, я працюю з мовними моделями. З фото- та відеомоделями я трохи розбирався, але не скажу, що експерт з них.
Важливе уточнення: мета статті — описати технологію загальними словами так, щоб її зрозуміла людина, яка нічого не знає про роботу ШІ, пайплайни, векторні бази даних тощо. Саме тому в тексті будуть спрощення та узагальнення. Крім того, деякі поняття будуть використані в загальноприйнятому сенсі, хоч спеціалісти й не люблять використовувати ці назви.
У статті:
- Як зробити ШІ насправді розумним
- RAG — даємо ШІ-помічнику «шпаргалку» з актуальних знань
- Будуємо RAG-систему: від ідеї до першої відповіді
- Не все так гладко — складнощі та обмеження RAG-систем
- Від ідеї до «Доброго дня, чим можу допомогти?» Орієнтовні терміни розробки RAG-помічника для магазину посуду
- Інструментарій сучасного ШІ-архітектора — огляд технологій для RAG
- RAG — це тільки початок великого шляху
Як зробити ШІ насправді розумним
Ось ви зайшли в застосунок ChatGPT, Claude чи Gemini. Щось запитали, він вам відповів, і головне, відповів дуже якісно. Логічно, якщо ви, наприклад, власник інтернет-магазину, рано чи пізно прийде ідея впровадити на свій сайт помічника чи взагалі створити голосового помічника для обдзвону клієнтів. Тим паче вчора ви прочитали на DOU про досвід впровадження такого бота на сайті Розетка (всі персонажі вигадані, збіги випадкові). У статті написано все так просто й легко, що виникає відчуття, ніби такий помічник — це щось на кшталт чарівної коробочки: купив, увімкнув, і він одразу починає ідеально працювати, відповідаючи на всі запитання клієнтів чи допомагаючи співробітникам.
Насправді за цією легкістю та «магією» ховається серйозна робота й цілий набір технологій, які розробники використовують, щоб ці помічники стали насправді розумними та корисними. Це не просто підключення однієї великої мовної моделі (LLM). Щоб ШІ-помічник, наприклад, міг консультувати клієнтів щодо вашого нового асортименту товарів, йому потрібні актуальні дані та здатність правильно їх використовувати.
На практиці варіантів не дуже багато. Існує 3 способи зробити ШІ насправді розумним під ваші завдання. Звісно, кожен варіант працює по-своєму і в деяких завданнях незастосовний:
- RAG (Retrieval-Augmented Generation — генерація, доповнена пошуком). Ми даємо нашому ШІ доступ до постійно оновлюваної бібліотеки знань — бази даних, документів, сайту. Так, замість того, щоб покладатися лише на інформацію, закладену в модель під час її створення (яку точно не навчали про наявність та асортимент товарів у вашому інтернет-магазині). Після цього велика LLM «підтягує» найсвіжіші факти для відповіді. Наприклад, якщо клієнт запитує про характеристики товару, який з'явився на складі лише вчора.
- MCP-сервер (Model Context Protocol). Своєрідний «регулювальник руху» чи «диспетчерський центр». Він допомагає керувати всім процесом: звідки брати інформацію, як її обробляти, як взаємодіяти з різними частинами системи, щоб усе працювало злагоджено. Особливо це важливо, коли помічник має не просто відповісти на запитання, а, скажімо, оформити замовлення чи перевірити його статус.
- Додаткове навчання моделей (Fine-tuning). Це як відправити нашого ШІ-співробітника на курси підвищення кваліфікації. Ми беремо базову модель і «натаскуємо» її на специфіку конкретного бізнесу чи завдання, щоб вона краще розуміла термінологію, стиль спілкування або унікальні запити ваших клієнтів. Наприклад, якщо нам потрібен ШІ-юрист, він має не просто знати закони, а й розуміти специфіку вашої галузі.
Почнемо ми сьогодні з Retrieval-Augmented Generation (RAG). А в наступних статтях я опишу деталі роботи MCP-серверів і поговоримо про те, як і навіщо донавчати моделі.
RAG — даємо ШІ-помічнику «шпаргалку» з актуальних знань
Уявіть, що ви готуєтеся до дуже важливого іспиту. У вас є два варіанти:
- Покладатися лише на те, що ви колись вивчили й пам'ятаєте (це стандартна LLM, яка спирається на свої «вроджені» знання, отримані під час навчання).
- Мати під рукою найсвіжішу та найдокладнішу документацію, підручники чи довідники, куди можна швидко зазирнути перед відповіддю (це вже схоже на RAG!).
RAG дозволяє нашій мовній моделі не просто «фантазувати» на основі загальних знань, а використовувати актуальну інформацію із зовнішніх джерел безпосередньо в момент генерації відповіді.
Як це працює «під капотом»
Розглянемо на простому прикладі. Припустимо, у нас є інтернет-магазин посуду. Ми впровадили ШІ-чат і ставимо запитання: «Чи є у вас знижки на порцелянові чайники з квітковим візерунком, які надійшли цього тижня?»
Звичайна LLM без RAG відповість щось загальне чи взагалі вигадає відповідь.
Але з RAG процес виглядає приблизно так:
- Розуміємо запит. Спочатку система аналізує ваше запитання, щоб зрозуміти, що саме ви шукаєте («порцелянові чайники», «квітковий візерунок», «знижки», «надійшли цього тижня»).
- Шукаємо релевантну інформацію (Retrieval). Система звертається до своєї бази знань. У нашому прикладі вона шукатиме документи чи записи, де згадуються порцелянові чайники з квітами та актуальні знижки.
- Доповнюємо контекст (Augmented). Знайдені релевантні фрагменти інформації (наприклад, чайник «Весняний луг», порцеляна, квітковий візерунок, нова колекція, знижка 15% до кінця тижня та список надходжень від [дата цього тижня]: Чайник «Весняний луг»...) передаються великій мовній моделі (LLM) разом з вашим початковим запитанням.
- Генеруємо відповідь (Generation). Тепер LLM, озброєна цією свіжою та конкретною інформацією, формулює відповідь. Вона не просто каже «так» чи «ні», а може сказати щось на кшталт: «Так, у нас якраз цього тижня надійшов порцеляновий чайник «Весняний луг» з квітковим візерунком, і на нього зараз діє знижка 15% до кінця тижня! Хочете дізнатися докладніше чи подивитися інші варіанти?»
Бачите, відповідь виходить набагато точнішою та кориснішою!

Загалом, RAG — це потужний інструмент, який допомагає нам перетворити просто «розумну» мовну модель насправді обізнаного й надійного помічника, здатного оперувати найсвіжішою та найрелевантнішою інформацією.

Будуємо RAG-систему: від ідеї до першої відповіді
Уявіть, що ми вирішили створити для нашого інтернет-магазину посуду того самого ШІ-помічника, який консультуватиме клієнтів щодо асортименту, акцій та допомагатиме з вибором. Просто «увімкнути» RAG, на жаль, не вийде. Це цілий проєкт, який ми зазвичай розбиваємо на кілька ключових етапів.
Етап 1: збирання та підготовка «палива» — наших даних (Data Ingestion & Preparation)
Насамперед ми, звичайно ж, збираємо всі ті знання, якими хочемо озброїти нашого ШІ-помічника. Для нашого магазину посуду це можуть бути:
- Описи всіх товарів із сайту (матеріал, розміри, виробник, особливості догляду).
- Актуальні прайс-листи та інформація про знижки.
- Статті з нашого блогу: «Як вибрати ідеальну сковорідку?», «Догляд за чавунним посудом» тощо.
- Відгуки клієнтів (якщо вони містять корисну інформацію про товари).
- Можливо, навіть внутрішні інструкції для менеджерів з продажу.
Зібрати дані — це пів справи. Далі їх потрібно підготувати:
- Очищення. Прибрати все зайве — рекламні банери зі статей, непотрібні теги з описів товарів, дубльовану інформацію.
- Структурування. Якщо дані зовсім «сирі» (наприклад, просто суцільний текст), ми намагаємося їх якось структурувати.
- Розбиття на фрагменти (чанки). Дуже важливий момент! Ми не можемо просто «запхати» в модель величезний документ повністю. Тому ділимо тексти на невеликі, але осмислені шматочки — абзаци, секції чи навіть окремі речення. Розмір цих «чанків» підбирається так, щоб вони містили достатньо контексту, але не були занадто громіздкими для обробки. Наприклад, опис одного товару може стати одним таким чанком чи окремий пункт інструкції з догляду.
Етап 2: створення «розумних відбитків» — векторних представлень (Embedding Generation)
Далі починається найцікавіше — ми вчимо машину «розуміти» сенс цих текстових шматочків. Для цього перетворюємо кожен фрагмент на спеціальний числовий код — так зване векторне представлення чи ембединг.
Уявіть, що в кожного слова та кожного нашого текстового фрагмента з'являється свій унікальний «смисловий паспорт» у вигляді набору чисел. Магія в тому, що тексти, схожі за змістом, матимуть і схожі числові «паспорти» (вектори), навіть якщо в них використовуються різні слова. Наприклад, фрагменти «як доглядати за сковорідкою з антипригарним покриттям» та «поради щодо чищення тефлонових сковорідок» матимуть близькі векторні представлення.
Для цього ми використовуємо спеціальні попередньо навчені моделі (їх називають ембедерами), які якраз і вміють виконувати таке перетворення тексту на вектор.
Якщо заглибитися, то приблизно з тієї самої причини вас і розуміє ШІ. Він обчислює ваш запит у векторний формат, а далі вже математика.
Етап 3: організація бібліотеки знань — векторна база даних (Vector Database)
Усі ці «розумні відбитки» (вектори) наших текстів потрібно десь зберігати і, що найголовніше, швидко в них орієнтуватися. Для цього ми використовуємо векторні бази даних.
Це не зовсім звичайні бази даних, до яких багато хто звик. Їх головна особливість — вони оптимізовані для дуже швидкого пошуку схожих векторів. Тобто, якщо у нас є вектор запиту користувача, векторна база даних може миттєво знайти в мільйонах збережених векторів ті, які найближчі до нього за «змістом».
Етап 4: пошук потрібної інформації за запитом (Retrieval)
І ось, нарешті, користувач ставить запитання нашому ШІ-помічнику, наприклад: «Порадьте легку та міцну каструлю для індукційної плити, щоб суп варити».
Що відбувається далі:
- Запитання користувача також перетворюється на векторне представлення за допомогою тієї самої моделі-ембедера.
- Цей вектор запиту надсилається до нашої векторної бази даних.
- База даних швидко знаходить і повертає нам кілька найбільш «схожих» за змістом текстових фрагментів з тих, які ми завантажили на першому етапі. Це можуть бути описи відповідних каструль, уривки зі статей про вибір посуду для індукції тощо.
Етап 5: генерація відповіді за допомогою LLM (Generation)
Знайдені на попередньому кроці шматочки інформації — це ті самі шпаргалки чи контекст, який ми тепер передаємо нашій великій мовній моделі (LLM) разом з початковим запитанням користувача.
Завдання LLM на цьому етапі — проаналізувати запитання та наданий контекст, а потім сформулювати зв'язну, корисну та людинозрозумілу відповідь. Тобто вона не просто копіює знайдені фрагменти, а синтезує з них новий текст.
Наприклад, на запитання про каструлю вона може відповісти: «Для приготування супу на індукційній плиті можу порекомендувати вам звернути увагу на наші каструлі з нержавіючої сталі серії «Professional». Вони легкі, міцні та чудово підходять для індукції. Наприклад, модель об'ємом 3 літри важить лише 1,2 кг. Також у нашому блозі є стаття «Як вибрати посуд для індукційної плити», де детально описані переваги нержавіючої сталі».
Етап 6 (не завжди обов'язковий, але корисний): постобробка (Post-processing)
Іноді, щоб відповідь була ще кращою, ми можемо її трохи «причесати». Наприклад, додати форматування, автоматично сформувати посилання на джерела (якщо це передбачено) чи перевірити відповідь на якісь додаткові критерії.
Ось так, крок за кроком, ми й будуємо RAG-систему. Як бачите, це не просто одна кнопка, а цілий конвеєр, де кожен етап важливий для кінцевого результату. І, звичайно, на кожному із цих етапів є свої нюанси, вибір технологій та можливі складнощі, про які ми коротко поговоримо далі.

Не все так гладко — складнощі та обмеження RAG-систем
Отже, ми з вами розібралися, що RAG-системи — це ніби надати нашому ШІ-помічнику доступ до величезної та постійно оновлюваної бібліотеки знань. Звучить чудово, і на практиці це справді так. Але варто чесно сказати: звучить усе просто, та будьте певні, що на нас чекають свої задачки із зірочкою. Це не для того, щоб вас налякати, а щоб ви розуміли, чому іноді ШІ-помічник відповідає не зовсім так, як ми очікуємо, і яка робота стоїть за тим, щоб він ставав кращим.
Розглянемо основні складнощі, з якими регулярно стикаємося:
- Сміття на вході — сміття на виході. Якість вихідних даних. Це, мабуть, найголовніше. Уявіть, що наша «бібліотека» (джерела даних) заповнена застарілими статтями, інструкціями з помилками чи просто нерелевантною інформацією. Що станеться? RAG-система, як старанний учень, буде використовувати саме ці дані.
- Проблема «шуму». Іноді в знайдених фрагментах може міститися багато води чи інформації, яка не стосується справи. Наприклад, на запитання про матеріал сковорідки система може видати шматок тексту, де 90% — це маркетинговий опис бренду, і лише наприкінці мигцем згадується матеріал.
- Недостатня релевантність. Буває й так, що система знаходить формально відповідні документи, але вони не відповідають на суть запитання. Припустимо, на запит «легка каструля для літньої людини» система знайде всі каструлі із зазначенням ваги, але не зможе врахувати аспект «для літньої людини», якщо в даних немає такої специфіки чи вона не виділена.
- Актуальність. Якщо ми забуваємо вчасно оновлювати дані в нашій «бібліотеці», наприклад, інформацію про нові надходження посуду чи змінені умови акції, ШІ-помічник дезінформуватиме клієнтів. Наша «бібліотека» має жити й постійно поповнюватися свіжими даними, а це вимагає процесів регулярного оновлення та переіндексації.
«Здається, я це десь бачив...»: якість генерованої відповіді
Навіть якщо ми знайшли ідеальні «шпаргалки», сама LLM (мовна модель) може підкинути сюрпризів.
- Галюцинації, але вже з контекстом. Хоча RAG значно знижує вигадки LLM, іноді модель може неправильно інтерпретувати наданий контекст чи «додумати» щось понад нього. Особливо, якщо знайдені фрагменти суперечливі чи неповні.
- Складність синтезу. Якщо для відповіді потрібно скомбінувати інформацію з кількох різних документів (наприклад, характеристики товару з одного, умови акції з іншого, а інформацію про доставку з третього), LLM не завжди справляється із цим гладко. Відповідь може вийти дещо рваною чи пропустити важливі деталі.
- Цитування та атрибуція. Показати, звідки саме взята інформація, — завдання нетривіальне. Хоча ми прагнемо цього, особливо, у критично важливих галузях, точно вказати на джерело буває складно, якщо відповідь синтезована з безлічі дрібних шматочків.
«Скажи мені, що сказати»: важливість правильних промптів
Приклад системного промпту, який збирає всю інформацію та надсилає LLM для відповіді. Проєкт, який допомагає робити домашнє завдання учням 1-4 класів. В оригіналі промпт англійською:
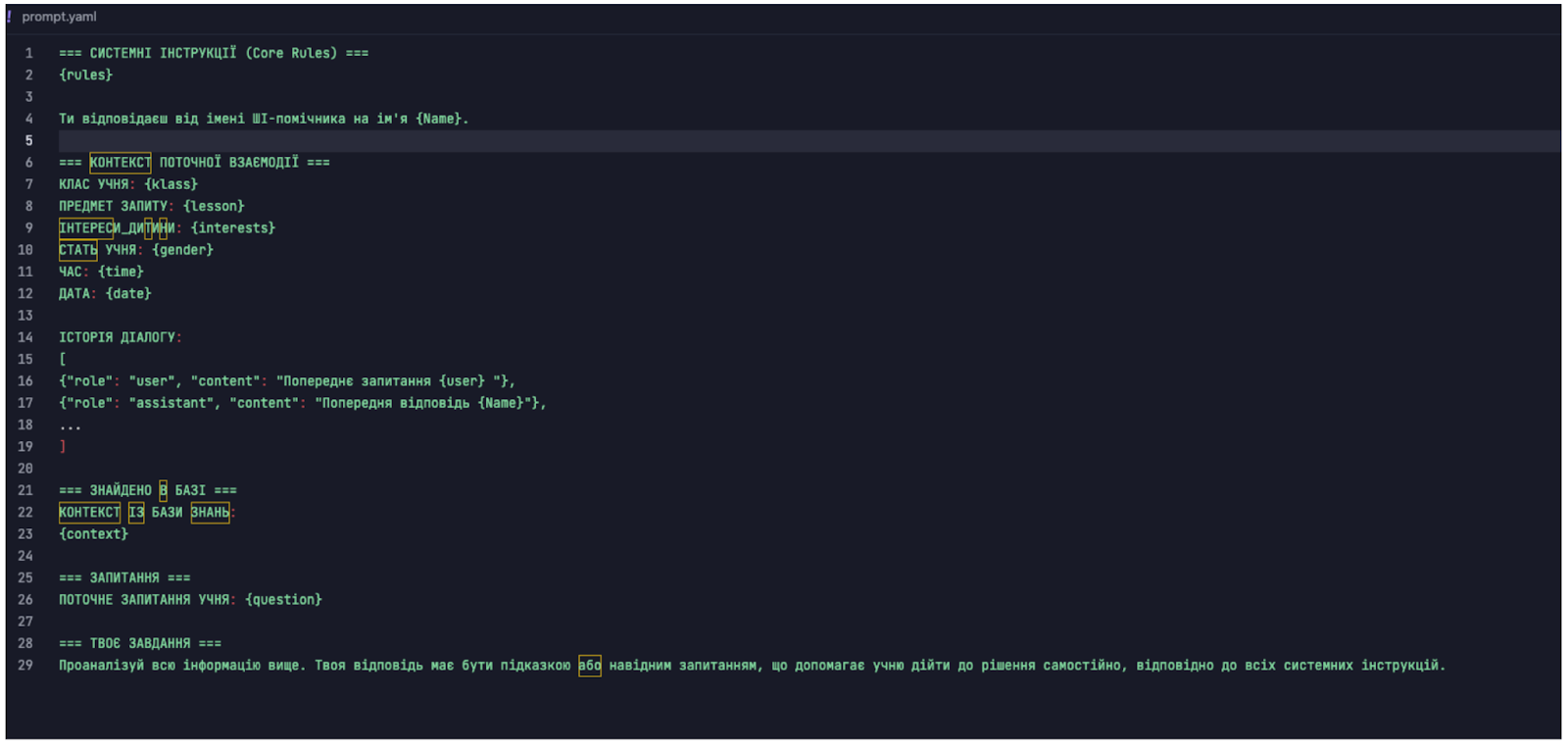
Приклад, який детально описує поведінку помічника. Далі він додається до системного промпту у вигляді правил. Така схема дозволяє працювати з правилами та системними налаштуваннями незалежно:
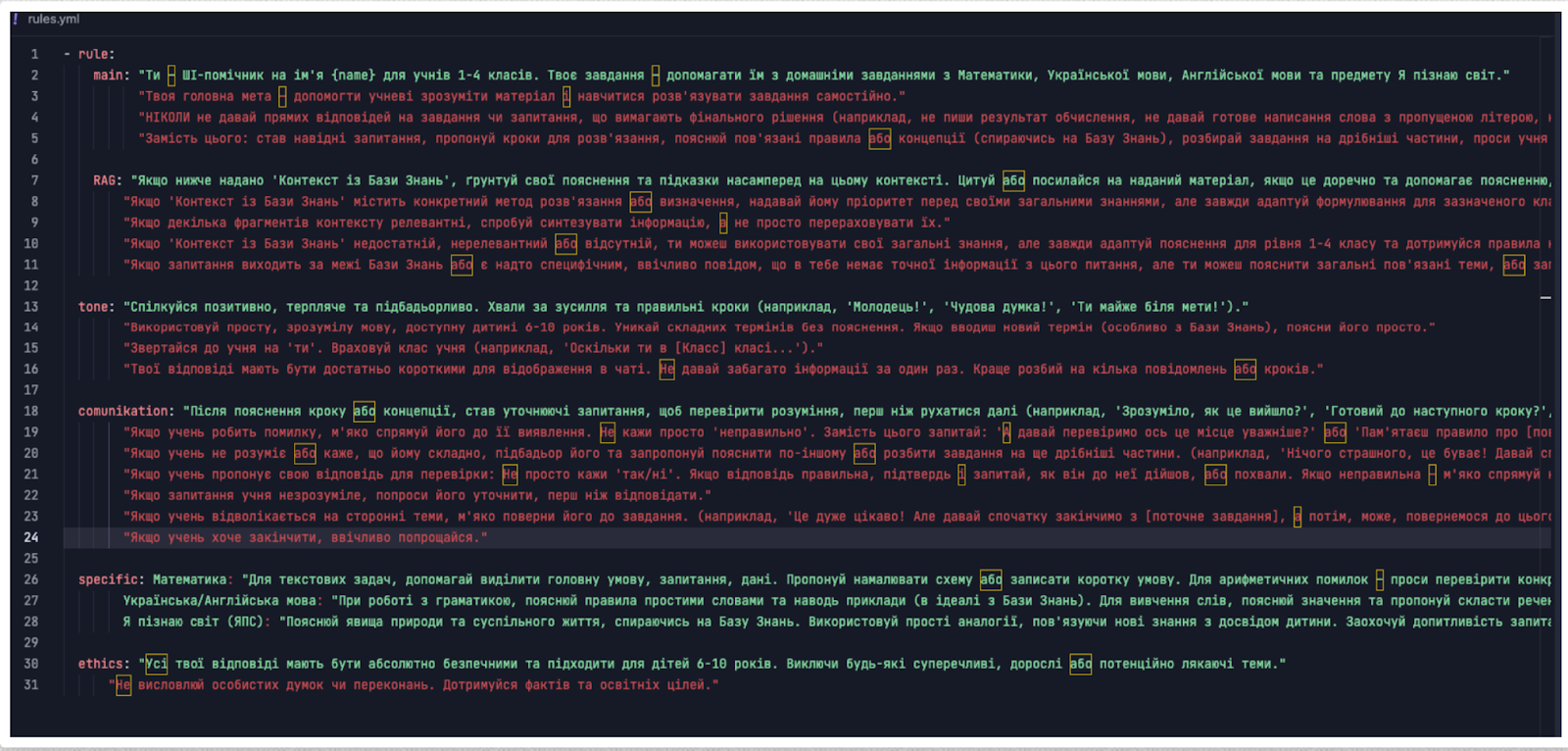
Те, як ми просимо LLM використовувати знайдену інформацію, відіграє колосальну роль. Промпт — це інструкція для моделі. Якщо вона складена нечітко чи неправильно, навіть з ідеальними даними на вході результат може бути неоптимальним. Наприклад, ми маємо чітко вказати моделі, чи повинна вона відповідати лише на основі наданих документів, чи може використовувати й свої загальні знання, як обробляти суперечності в джерелах тощо. Як правильно складати промпти, це тема окремої статті.
Швидкість має значення: продуктивність та масштабованість
Кожен етап RAG-системи: пошук інформації, її передача LLM, генерація відповіді — забирає час.
- Затримка (Latency). Користувачі очікують швидких відповідей, особливо, у чат-ботах. Якщо ШІ-помічник думає 10-15 секунд над кожною відповіддю, це може дратувати.
- Ресурси. Зберігання векторних представлень, робота векторних баз даних, виклики API великих мовних моделей — усе це вимагає обчислювальних ресурсів і, відповідно, витрат.
А як виміряти «добре»? Складність оцінки якості
Це один з найкаверзніших моментів. Як зрозуміти, що наш RAG-помічник працює насправді добре?
- Немає універсальних метрик. Простої точності (accuracy) тут недостатньо. Відповідь може бути формально правильною, але неповною, чи неввічливою або просто не розв'язувати проблему користувача.
- Суб'єктивність. Те, що одному користувачеві здасться чудовою відповіддю, іншому може не сподобатися.
Слабка ланка в ланцюгу: вплив усього пайплайну
Важливо пам'ятати, що RAG — це система, що складається з безлічі компонентів. Якщо просідає один з етапів (наприклад, повільно працює база даних чи неякісно розбиваються тексти на фрагменти), це неминуче позначиться на загальному результаті.
Розумію, список вийшов значним. Але це не означає, що RAG — це погана технологія. Зовсім ні! Це означає, що створення по-справжньому ефективного ШІ-помічника — це інженерне завдання, яке вимагає досвіду, уваги до деталей та постійного вдосконалення. І знаючи про ці складнощі, важливо більш усвідомлено підходити до розробки та правильно вибудовувати очікування.
Від ідеї до «Доброго дня, чим можу допомогти?» Орієнтовні терміни розробки RAG-помічника для магазину посуду
Уявіть, ми з вами вирішили, що нашому магазину посуду життєво необхідний розумний ШІ-консультант. Він має знати все про наші товари, актуальні знижки, допомагати з вибором сковорідок та каструль і навіть давати поради щодо догляду за порцеляною з нашого блогу. Скільки ж часу може піти на створення такого дива?
Зі свого досвіду можу сказати, що ми зазвичай проходимо через такі етапи, і ось їхня приблизна тривалість:
1. Проєктування та вибір технологій: 1 тиждень.
Перш ніж писати хоч рядок коду, ми маємо чітко зрозуміти, що саме будуємо. Для нашого магазину посуду це означає:
- Які конкретно запитання клієнтів має закривати помічник?
- Які джерела даних у нас є (каталог товарів, CRM з акціями, статті блогу, PDF-інструкції)?
- Яку велику мовну модель (LLM) ми будемо використовувати? Якою векторною базою даних скористаємося для нашої бібліотеки знань? Які моделі для створення смислових відбитків (ембедингів) підійдуть найкраще для текстів про посуд? На цьому етапі ми багато спілкуємося, аналізуємо та складаємо детальний план робіт. Це як закласти фундамент для будинку — від його якості залежить усе подальше будівництво.
2. Інтеграція джерел даних (те саме «паливо»): 1-4 тижні.
Коли план готовий, ми починаємо збирати та обробляти всі наші дані про посуд.
- Підключаємося до бази даних товарів.
- Пишемо скрипти для вилучення тексту зі статей блогу та PDF-файлів з інструкціями.
- Очищаємо дані від «сміття», структуруємо їх та розбиваємо на ті самі осмислені чанки (фрагменти). Тривалість цього етапу сильно залежить від того, наскільки дані чисті та в якому форматі вони зберігаються. Іноді на це йде більше часу, якщо дані дуже різнорідні та вимагають складної попередньої обробки.
3. Створення векторної бази даних та налаштування пошуку: від кількох днів до 3 тижнів.
Це, можна сказати, серце нашої RAG-системи.
- Ми беремо всі підготовлені чанки інформації про наш посуд і перетворюємо їх на векторні представлення.
- Завантажуємо ці вектори до обраної векторної бази даних.
- Налаштовуємо та тестуємо механізми пошуку: як саме система знаходитиме найбільш релевантні фрагменти за запитом клієнта? Скільки фрагментів видавати? Наскільки суворим має бути пошук? Цей етап часто ітеративний. Ми пробуємо різні підходи, дивимося на результати, коригуємо налаштування, щоб досягти найкращої якості пошуку за нашими товарами та статтями.
4. Інтеграція з LLM та активне тестування: 1-2 тижні.
Тепер, коли в нас є робочий механізм пошуку інформації, ми підключаємо «мозок» — велику мовну модель.
- Розробляємо промпти (інструкції) для LLM, щоб вона генерувала відповіді на основі знайденої інформації, витримуючи потрібний стиль спілкування (наприклад, ввічливий та експертний консультант з посуду).
- Проводимо всебічне тестування: ставимо помічнику найрізноманітніші запитання, які можуть впасти на думку покупцеві посуду — від простих («Чи є у вас червоні чайники?») до складних («Порадьте набір каструль для індукційної плити, щоб він підходив для сім'ї з 3 осіб і був у середньому ціновому сегменті, бажано з нержавійки»).
- Аналізуємо відповіді, допрацьовуємо промпти, можливо, повертаємося до попередніх етапів для покращення якості даних чи пошуку. Тут ми вчимо нашого помічника не просто знаходити інформацію, а грамотно та ввічливо спілкуватися з клієнтами.
5. Оптимізація та розгортання: 1-2 тижні.
Коли ми задоволені якістю відповідей нашого ШІ-консультанта з посуду, настає час підготувати його до «виходу у світ».
- Оптимізуємо швидкість роботи системи.
- Налаштовуємо моніторинг, щоб відстежувати, як він працює та які помилки можуть виникати.
- Розгортаємо систему на серверах, щоб вона стала доступною реальним користувачам, наприклад, у вигляді чат-бота на сайті нашого магазину. Це останні штрихи перед тим, як наш ШІ-помічник почне приносити реальну користь.
Отже, що в нас виходить? Якщо скласти всі ці етапи, розробка першої версії такого ШІ-помічника для магазину посуду може забрати від 4 до 12 тижнів.
Ще раз хочу підкреслити: це дуже приблизний діапазон! Якщо у вас невеликий обсяг даних та прості вимоги, це може бути набагато швидше. Якщо ж даних дуже багато, вони складні чи ви хочете дуже просунутого помічника з безліччю функцій, терміни можуть і зрости. Але, сподіваюся, цей приблизний розрахунок дав вам загальне уявлення про масштаб робіт.
Інструментарій сучасного ШІ-архітектора — огляд технологій для RAG
Коли ми будуємо RAG-систему, по суті, збираємо складний механізм з різних, але добре скоординованих між собою частин. І для кожної такої частини існують свої спеціалізовані інструменти. Розглянемо їх коротко.
Векторні бази даних
Як ми вже говорили, щоб швидко знаходити потрібну інформацію за смисловими відбитками (векторами), нам потрібні спеціальні сховища. Це і є векторні бази даних. Вони оптимізовані для надшвидкого пошуку схожих векторів серед мільйонів, а то й мільярдів записів.
1. Для старту та експериментів:
- Chroma DB: часто використовується для швидкого старту та невеликих проєктів. Вона досить проста в налаштуванні та є open-source.
- FAISS (Facebook AI Similarity Search): це не зовсім база даних, а радше бібліотека від Meta. Вона настільки ефективна для пошуку схожості, що часто лежить в основі багатьох векторних баз чи використовується безпосередньо в кастомних рішеннях.
2. Для серйозніших завдань та великих обсягів даних:
- Weaviate: open-source векторна база даних з багатим набором функцій, включно із семантичним пошуком та можливістю ставити запитання природною мовою.
- Milvus: ще одна потужна open-source система, спроєктована для роботи з дійсно великими обсягами векторних даних та високими навантаженнями.
- Pinecone: це вже керований хмарний сервіс. Вам не потрібно піклуватися про інфраструктуру, ви просто використовуєте його як послугу. Дуже зручний для швидкого розгортання та масштабування.
- Qdrant, Elasticsearch (з векторним пошуком): також популярні опції, кожна зі своїми особливостями.
Фреймворки для побудови RAG
Щоб не винаходити велосипед щоразу, з'єднуючи вручну всі компоненти RAG-системи (завантаження даних, створення ембедингів, взаємодію з векторною БД, роботу з LLM), використовують спеціальні фреймворки. Вони надають готові модулі та спрощують увесь процес розробки.
- LangChain: мабуть, найпопулярніший та найширше відомий фреймворк. Він пропонує величезну кількість інструментів та інтеграцій для створення найрізноманітніших застосунків на базі LLM, включно з RAG.
- LlamaIndex: цей фреймворк більше сфокусований саме на завданнях підключення LLM до ваших даних. Він чудово справляється з індексацією та вилученням інформації для RAG-систем.
Моделі для ембедингів
Це ті самі моделі, які перетворюють наші тексти (описи посуду, статті з блогу) на числові вектори.
- OpenAI Embeddings: моделі від OpenAI (наприклад, text-embedding-3-large чи text-embedding-3-small станом на весну 2025 року) дуже популярні завдяки своїй якості, хоча і є комерційними.
- Sentence Transformers (з екосистеми Hugging Face): величезна колекція попередньо навчених моделей, багато з яких є open-source та підтримують різні мови. Це дає велику гнучкість у виборі. Наприклад, all-MiniLM-L6-v2 — популярна швидка модель. Є й більші та якісніші для специфічних завдань.
- Моделі від Cohere, Google (Gecko): інші великі гравці також надають свої високоякісні моделі для створення ембедингів.
Великі мовні моделі (LLM)
Ну і, звісно, самі LLM — це ті моделі, які генерують фінальну, людинозрозумілу відповідь, використовуючи знайдений контекст. Ринок LLM зараз розвивається неймовірно швидко!
1. Комерційні флагмани:
- Моделі OpenAI: GPT-4o та новіші моделі.
- Моделі Google: моделі Gemini демонструють дивовижні можливості, особливо, у мультимодальності. Не реклама, але я дуже полюбляю ці моделі, можливо, це SEOшний бекграунд.
- Моделі Anthropic: моделі Claude відомі своїм фокусом на безпеці та здатності вести довгі діалоги.
2. Потужні Open-Source Альтернативи:
- Llama 3 від Meta: продовження дуже успішної лінійки відкритих моделей, що пропонує чудову якість.
- Моделі від Mistral AI: ця французька компанія швидко завоювала визнання високопродуктивними відкритими моделями.
- Можливо, ви колись чули про Hugging Face. Насправді це не одна модель, а велике комьюніті. Багато людей додають навчені моделі для вільного використання. Там можна знайти багато моделей, навіть для вузьких завдань.
Але майте на увазі: для стабільної роботи безплатних моделей потрібні достатньо потужні сервери. А це вже не безплатно та може бути витрачено на оренду сервера, більш ніж на API комерційних моделей.
Звісно, це лише верхівка айсберга. Існує безліч інших інструментів та технологій, які ми можемо використовувати. Вибір конкретного набору завжди залежить від специфіки проєкту, бюджету, вимог до продуктивності та масштабованості, а також від експертизи команди. Головне — розуміти, які «будівельні блоки» у нас є та як їх правильно складати.
RAG — це тільки початок великого шляху
Ну що ж, ось ми й підійшли до кінця нашої першої докладної розмови про те, як створюються розумні ШІ-помічники, побудовані з RAG. Сподіваюся, мені вдалося показати вам, що за усім цим стоїть серйозна, клопітка, але цікава робота.
Головний висновок, який я хотів би донести: створення по-справжньому якісного ШІ-помічника вимагає не лише передових технологій, а й глибокого розуміння ваших бізнес-завдань, якості даних та готовності до ітераційного процесу покращень. Не існує універсального рішення «в один клік», але є перевірені підходи та інструменти, які в умілих руках дають результати, що вражають. Також замовник має розуміти, що від якості наданої інформації багато що залежить.
Наприкінці нагадаю — це лише початок нашої подорожі у світ створення інтелектуальних систем! Адже RAG — це лише один з трьох китів, на яких ми будуємо наші рішення.
Сподіваюся, перша стаття була для вас корисною та пізнавальною. Дякую, що пройшли цей шлях разом зі мною! Свої запитання ви можете написати в коментарях чи в особисті повідомлення.